
Hace unos días atrás, por primera vez escucho sobre un nuevo programa en la CSS para lo que tiene que ver con las planillas. En televisión y en los periódicos veo cantidades enormes de empleadores quejándose de este sistema nuevo sistema que se supone facilitaría las cosas. Cuando los empleadores iban al pago de las planillas, habia toda clase de problemas (http://www.laestrella.com.pa/online/impreso/2012/09/27/molestias-y-quejas-por-mal-servicio-de-la-css.asp). En Twitter las quejas abundaban. No faltaba el típico “se cayó el sistema”. Una de las excusas que dieron fue que las computadoras no tenían capacidad. Un poco ambiguo me pareció esa excusa. Unos días después se cae nuevamente el sistema, esta vez la excusa fué un problema en el servidor. ¿Servidor? ¿En singular? Aquí las cosas se empiezan a ver preocupantes. ¿Cómo algo que costó 5 millones está en un único servidor? Bueno, puede ser que haya más pero no lo mencionaron en la nota de televisión.
La explicación de un fracaso desde el punto de vista técnico
Todavia no le presté mucha atención al tema, hasta que en la oficina por primera vez ví el SIPE. Era una aplicación web. Si es una apliación web entonces, ¿cómo pudieron decir que era porque los usuarios no tenían capacidad? Eso lo ví como un insulto a la población, así que como desarrollador web, quería ver quién tiene la razón, así que empece a analizar el SIPE, desde el punto de vista técnico, y he aquí mis resultados. Cabe destacar que esto es meramente una opinión personal.
Nota: En este artículo no colocaré imágenes de la interfaz del SIPE pues, al ser una aplicación web, están protegidas por el marco legal del derecho de autor, y no cuento con la autorización escrita para poder utilizar imágenes de la aplicación en este momento. Además, con las recién sacionadas modificaciones a la ley de propiedad intelectual, mejor cuidarse en salud.
Un Sistema que no vale ni 100 mil dólares
Una de las primeras cosas que me llamó la atención fueron los 5 millones de dólares que costó este sistema. Por tal elevado costo me imaginé una aplicación espectacular con una infraestructura de lujo. Lo que encontré es totalmente opuesto y una vez más demuestra que nos han “congueado”.
Cuando ví el SIPE funcionando por primera vez, una de las primeras cosas que noté era lo horriblemente lento que cargaba la página de inicio. Lo primero que hice entonces fue analizar el tráfico entre el servidor y el navegador para ver porqué demoraba tanto en cargar. Lo que encontré fue de espanto, y lo podemos apreciar en la imagen de abajo.
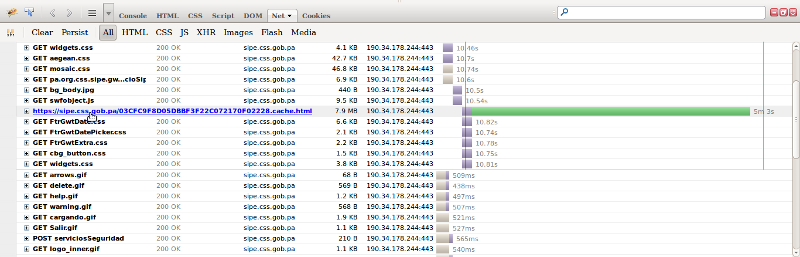
7.9 MB envía SIPE desde el caché. ¿Por qué tanto?* (haz clic en la imagen para verla en grande)*
Si te fijas donde está el puntero, el SIPE literalmente le envió a mi navegador 7.9 MB de contenido en una llamada. Eso es casi dos canciones de 4 minutos en mp3. Yo asombrado quise ver qué clase de contenido me estaba enviando. Mi primera suposición fue que me estaba enviando el código javascript de la aplicación (javascript es un lenguaje de programación). Me extrañó que pesara tanto, en especial siendo una aplicación web que debería ser relativamente liviana. Bueno, revisé el contenido, y lo que pongo a continuación es sólo una mínima porción de lo que me estaba mandando el servidor del SIPE:
gc(){}
function Tgc(){}
function ahc(){}
function khc(){}
function uhc(){}
function Fhc(){}
function $hc(){}
function cic(){}
function gic(){}
function fic(){}
function Aic(){}
function Vic(){}
function Uic(){}
function Zic(){}
function cjc(){}
function X0e(){var b;nsi[b=++osi]=X0e;psi[b]=Wyi+Mxi,Hj(this);osi=b-1}
function a1e(){var b;nsi[b=++osi]=a1e;psi[b]=Wyi+Mxi,Hj(this);osi=b-1}
function f1e(){var b;nsi[b=++osi]=f1e;psi[b]=Wyi+Mxi,Hj(this);osi=b-1}
function k1e(){var b;nsi[b=++osi]=k1e;psi[b]=Wyi+Mxi,Hj(this);osi=b-1}
function p1e(){var b;nsi[b=++osi]=p1e;psi[b]=Wyi+Mxi,Hj(this);osi=b-1}
function u1e(){var b;nsi[b=++osi]=u1e;psi[b]=Wyi+Mxi,Hj(this);osi=b-1}
function A1e(){var b;nsi[b=++osi]=A1e;psi[b]=Wyi+Mxi,Hj(this);osi=b-1}
function C1e(){var b;nsi[b=++osi]=C1e;psi[b]=Wyi+Mxi,Hj(this);osi=b-1}
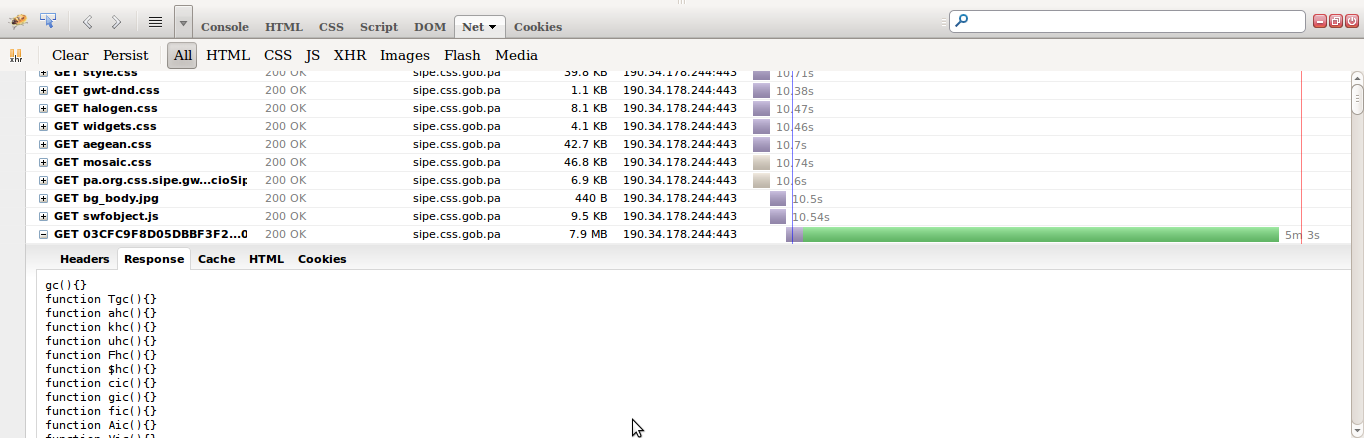
Sí. Eso es lo que literalmente habia en esos 7.9 MB de contenido
Si eres un programador, ahora mismo estas pensando lo mismo que yo. ¡Qué porquería! Si no eres programador, dejame explicarte que está sucediendo en esas líneas de programación. Las líneas cortitas que ves más arriba literalmente dice “haz nada”, 3473 veces. En las más largas, como que empieza a ocurrir algo, pero con esa clase de nomeclatura que están usando, no tengo ni la más mínima idea de lo que está pasando. ¿Qué puedo concluir de eso? Que ese código no fue hecho por personas, sino generado automáticamente por un programa. Cabe recalcar que en las aplicaciones web hay dos porciones de código, la del cliente (front-end), que es la que analicé, y la del servidor (backend), la cual no puedo analizar porque no cuento con el código fuente del programa. Pero por lo visto a primera, el front-end fue generado por un programa y no le metieron esfuerzo ni dedicación.
A los programadores: pensé que tal vez estaba creando classes de objetos (obviamente el código está obfuscado) para despues extenderlos via prototype, pero en todo el código, las 10729 líneas de código que encontré, nada más había 5 prototype, o sea que más aún creo que es basura intendendible. Sólo unas cuantas líneas al final tenian algo de sentido, pero seguían llamando estas funciones con nombres todo locos asi que no pude ver su propósito en el poco tiempo que estuve analizando.
Vamos a ver otro detalle importante. Aquí tengo una conexión de 3 MB, y me tomó 5 minutos y 3 segundos recibir el contenido del servidor (lo puedes observar en la barra verde en la imágen de arriba, y el tiempo justo después de esa barra). Si mi servidor tuviese que mandarle 7.9 MB de contenido a cada usuario que trata de iniciar sesión en el sistema, no tardaría mucho en que el servidor llegáse a su límite. Imagina entonces cuando miles de usuarios tratan de usar el sistema al mismo tiempo. No es de extrañar que a cada rato el sistema se ande cayendo. En total, sólo para entrar a la página de inicio, el servidor me envió 8.2 MB de información. Ni siquiera la página de Facebook envia tanto. Para un login a lo sumo deberia ser 100 KB por las imágenes. Lo que SIPE envía son casi 80 veces más cantidad de lo que cualquier otra página de login envía.
Ahora, yo no me considero un gurú o un sabelotodo en cuanto a desarrollo web, pero la calidad de trabajo que entregaron con el SIPE, pareciera que un poco de estudiantes de sistemas lo desarrollaron como un final para pasar un curso de Oracle. No tiene el más mínimo profesionalismo que debe tener de un software que viene de una empresa, mucho menos de uno que costó 5 millones de dólares.
¿La Plataforma menos popular?
Vamos a adentrarnos un poco más en lo que hace al SIPE ser, su plataforma de desarrollo. Revisando los headers (es un término técnico, puedes ignorarlo) encontré que el SIPE se encuentra hospedado en un servidor de Aplicaciones Oracle y el servidor HTTP de Oracle. Mi primera reacción: ¿¡ah!? ¿Oracle como servidor web para atender miles de conexiones concurrentes en diferentes redes? No me tomen a mal, Oracle se puede usar para ese propósito, pero nunca, en todos mis años de desarrollo, he visto que alguién tome esa decisión. ¿Por qué? Es por el escenario en donde se va a usar. Usualmente las aplicaciones de Oracle se usan en redes internas, y muy rara vez en una red pública. Déjame ser un poco más claro en eso. En algunas empresas hay ciertas aplicaciones que sólo pueden usarse dentro de la empresa, como por ejemplo, los ERPs (si así están configurados), el software que se usa en la caja registradora o punto de venta, etc. Usualmente esa clase de software se comunica con un servidor que esta instalado dentro de la empresa y que se piensa solamente se va usar dentro de la empresa. No es algo que permitirías que, por ejemplo, 100,000 empleadores lo usen en determinado momento porque simple y sencillamente no está hecho para eso. Sin embargo, hay servidores y software específico que están diseñados para atender esa clase de demandas, y para lograrlo, requiren de muchísima planificación. Un servidor de aplicaciones de Oracle usualmente se usa en el escenario interno, porque no esperas mucho tráfico (tráfico es la cantidad de computadoras solicitando información, por así decirlo; cuando tu navegas a una página, tu generas tráfico hacia esa página). Para aplicaciones que demandan alto tráfico, usualmente la decisión es otra, ya sea Apache o IIS. Es más, para esa aplicación yo francamente hubiera imaginado que iban a utilizar Nginx o LightHttp. No es que Oracle sea malo; simple y sencillamente hay mejores.
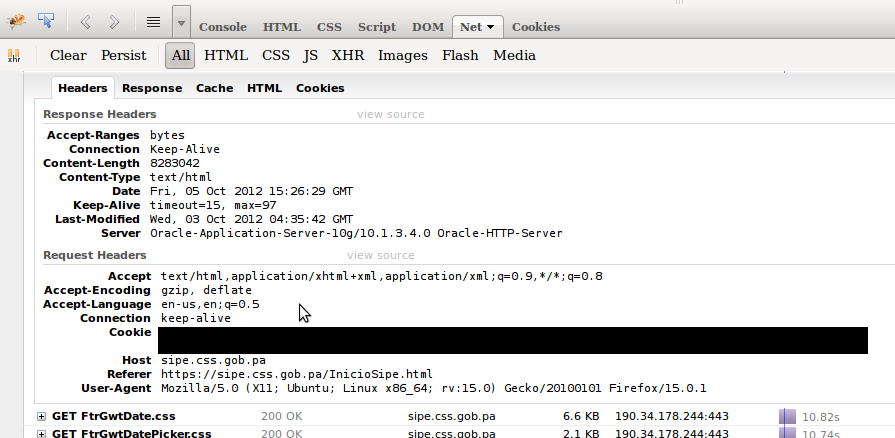
Como podemos apreciar en los headers, el servidor es Oracle, y el HTTPD también
¿Pero porqué usaron Oracle? Al entrar a la página de uno de los desarrolladores del sistema ví el porqué. Ellos venden Oracle. Es como si fueras a un carpintero a pedirle que te construya vigas para un edificio de 20 pisos. Lo que te va a entregar son vigas de madera, porque eso es lo que tiene y sabe hacer, no las vigas de acero reforzadas que necesitas. Oracle WebLogic, el servidor de aplicaciones de Oracle, en un sondeo entre las 1000 aplicaciones “enterprise” más populares, solamente se encontró en el 0.51% de las aplicaciones (http://blog.newrelic.com/wp-content/uploads/Death-of-proprietry-app-servers1.jpg). Este sondeo es de este año (Enero 2012). 0.51% y eso es lo que decidieron usar, porque obviamente es lo que venden y saben hacer, aún cuando hay mejores soluciones y gratis (Oracle es caro) para esta situación.
{kind=link}
El servidor está caído: el peor insulto a un cliente en esta era
Pero bueno, no se le puede echar toda la culpa a la plataforma (aunque mucha culpa tiene un software tan pésisamente optimizado y desarrollado). ¿Qué pasa con la infraestructura, es decir, cómo es eso de los servidores caídos? Bueno, cuando tu desarrollas una aplicación que espera muchísimo tráfico, hay muchas cosas que se toman en consideración. Por ejemplo, ¿es una aplicación que necesitar sacar e introducir mucha información de la base de datos? Obviamente sí, todos los empleados en el país. ¿Es el servicio tan escencial que no puede permitir fallas durante sus horas pico? Obviamente sí, sino el empleado se queda sin su cuota paga. ¿Necesita ser escalable, es decir, se puede asumir los costos de una arquitectura escalable? Sí, sí, y más sí, costo 5 millones, ¿no?. En base a preguntas como esas, tú vas ideando una arquitectura para asegurar que tu aplicación siempre funcione. En base a las características del SIPE, yo en lo personal me hubiera ido por una solución en la nube, por ejemplo Amazon AWS o Rackspace, que son datacenters multibillonarios que dan hospedaje a grandes páginas, como por ejemplo Amazon o Reddit.
Ahora, ¿por qué digo que la excusa del servidor está caído es un insulto al cliente? Una palabra: redundancia. Vivimos en una era tecnológica en donde siempre hay respaldo. Si un servidor se cae, hay un segundo y un tercero listos para recibir el tráfico del servidor caído, y el cliente ni cuenta se da que hay problemas en la infraestructura. Yo puedo darle mantenimiento a los servidores sin tener que tumbar el sistema (como ocurrió recientemente con mantenimiento que le estaban dando a la plataforma). Es más, ahora mismo puedo estar dando mantenimiento a varios servidores, y los clientes ni cuenta se van a dar que estoy haciendo eso. Eso se logra a través de la planificación de la arquitectura de tu servicio (no la arquitectura de red). Ahora, cuando digo servicio estoy hablando de la aplicación. Una aplicación es un servicio porque es algo que te permite hacer algo, o sea, te está sirviendo algo, ya sea un proceso o información. Cuando me refiero a la arquitectura del servicio es cómo voy a hacer que mi aplicación este disponible un 100% del tiempo en el año. ¿Por qué es tan escencial que un servicio esté disponible el 100% del año? Imagina Amazon por ejemplo. Si su servicio se cayera por solo una hora, millones de dólares en pérdidas sufriría Amazon. Imagina que tú tienes una tienda online que vende a un ritmo de $10 mil la hora, y tu proveedor del servicio se cae. Pierdes $10 mil por el mal servicio de tu proveedor. ¿Qué haces? Lo demandas. Lo mismo se aplica en este escenario, pero en este caso el que asume la pérdida es el empleador que tiene que lidiar con un sistema ineficiente, y no la CSS que es la que está brindando el servicio.
Ahora, como no tengo información de adentro o he visto el código fuente del SIPE, no hay mucho que pueda decir con certeza del diseño de la arquitectura. Sin embargo, en base a los testimonios y análisis de la información que me envía el servidor, puedo llegar a los siguientes puntos de que realmente es un servidor único.
- Usualmente, si hubiera redundancia, es decir más de un servidor, habria un dispositivo llamado Load Balancer que se encarga de distribuir el tráfico entre servidores. Por la velocidad de respuesta del servidor, esto probablemente no sea así. Con una conexión de 3.5 MB los 8.2 MB que me envió el SIPE debí haberlos recibido en menos de un minuto; fueron 5 minutos. Esto me indica la red donde está el servidor está a su máxima capacidad y no tiene suficienda ancho de banda de subida para atender los miles de empleadores en Panamá, o el servidor está en verdad a su límite.
- Que tumben el servicio el fin de semana para mantenimiento me dice que nada más tienen un servidor. Si fuese dos, uno estaría abajo durante el mantenimiento y el otro se encargaría de ofrecer el servicio.
Por cinco millones creo que debería haber algo de redundancia, ¿no? Y francamente no se qué mantenimiento le vas a dar al servidor. Le vas a dar es al software, lo que me dice que apenas están encontrando errores que tienen que reparar, a lo que me lleva al siguiente punto.
Un software crítico sin probar
Las empresas de desarrollo serias siguien metodologías de desarrollo comprobadas que ayudan a minimizar el impacto de errores en la programación. Existe un flujo de desarrollo, en donde una de las partes más importantes del proceso es el “testing”, o las pruebas como se dice en español. El o los programadores prueban todos los escenarios posibles para asegurarse que lo que programaron funcione; crean casos de estudio para sistemas automatizados de prueba, y algo más complejo llamado Unit Testing. Un caso de estudio es básicamente un escenario grabado, como por ejemplo un usuario introduciendo la planilla al sistema, o introduciendo o eliminando a un empleado. Lo que se hace es que se crean varios escenarios o casos de estudio, y se graban. Luego, a través de un software especializado de prueba, se reproducen esos casos de estudio y se genera un reporte. Si algo falla, estará en el reporte.
Cuando se trata de aplicaciones de alto tráfico existe un paso adicional llamado “stress testing”, o pruebas de estrés. Básicamente se toman los casos de estudio que se crearon, y se aplican simultáneamente como si varios usuarios estuvieran haciendo la misma ación al mismo tiempo. Se llama stress testing porque se hacen pruebas con múltiples usuarios automatizados, como por ejemplo 100 o 1,000 o incluso más para determinar cómo ejecuta la aplicación bajo esa situación. Al final se obtiene un reporte, y este permite determinar qué tan eficiente es la aplicación cuando se encuentra bajo estrés y que correciones se deben hacer, ya sea en la misma aplicación, o en la arquitectura del servicio. Una prueba de este tamaño podría estar costando aproximadamente $5,000, pero el precio lo vale pues te permite ofrecer un mejor servicio a tus usuarios, y si tomamos en cuenta que el SIPE costó 5 millones, entonces $5,000 no es nada.
Desafortunadamente, por lo que he visto, el stress testing no se hizo. Es más, pareciara que están improvisando y realizándolo con los usuarios reales como prueba, y ahora es que se dieron cuenta que la aplicación no soporta los miles de empleadores que necesitan usarla, y por eso, en poco tiempo, ya le están haciendo “manteminiento”, es decir, corrigiendo todos los errores que no se molestaron en probar, antes de lanzar el SIPE al público. ¿El resultado? Ya todos lo conocemos: miles de personas gastando tiempo inútilmente en filas, tratanto de utilizar el sistema, confusión, el sistema colapsado, mantenimientos de emergencia pos-lanzamiento para estabilizar la plataforma. Por 5 millones de dólares, nada de esto debió haber sucedido. Es más, lo que deberíamos estar escuchando es a la gente alabar el sistema, no criticarlo.
Es importante resaltar que la CSS intentó hacer la implementación de forma escalonada, incorporando a mil empleadores primero, luego unos meses después unos miles más, y después el resto. En desarrollo, esto es la etapa final. En esta etapa el sistema entra en producción, es decir, puede ser utilizado por los empleadores. No se le puede llamar beta testing pués se están realizando transacciones reales y no de prueba, que acarrean resultados reales y pueden llevar a pérdidas financieras. Ya esto es prueba en vivo. Lo que se hace durante esta fase es que la aplicación está funcionando a su capacidad, y se corrigen los pequeños errores que se ignoraron o no fueron descubiertos durante el desarrollo y las pruebas de los desarrolladores. Ya aquí no debería haber problemas serios, y en caso de haberlos, son corregidos en su totalidad. La CSS estaba en esta etapa cuando los primeros 1000 empleadores se encontraban utilizando este sistema. Antes de entrar al segundo grupo de empleadores (segunda etapa), ya el sistema debió haber estado corregido. De encontrarse errores en el segundo grupo, como decimos en buen panameño, la aplicación se hecha para atrás y no se continúa su implementación hasta que se esté 100% seguro de que esté funcionando. Obviamente esto no pasó. Sino, no estarían los empleadores echando chispa ahora mismo.
Cero Inversión en Usabilidad y Diseño
El desarrollo de las aplicaciones web conlleva muchas etapas. Aunque en muchos casos es posible que un único programador pueda llevar a cabo todas las etapas, a veces es mejor cuando múltiples personas forman parte del proceso.
Antes de empezar todo desarrollo, viene una parte importante: la planificación. Uno de los pasos finales de la planificación se llama User Experience, o experience del usuario. Sus siglas son UX, y es un campo muy amplio. UX tiene que ver con la usabilidad, que es básicamente la forma en que el usuario va a utilizar la aplicación o el servicio. Lo que se busca con la usabilidad es brindarle al usuario la mayor facilidad para usar la aplicación. Los expertos en usabilidad pasan días estudiando, bosquejando, diseñando, etc. cómo el usuario tendrá interacción con la aplicación, con tal de facilitarle lo más que pueda el uso de la herramienta, y simplificar la misma. Grandes empresas como Google, Facebook, Twitter, etc. tienen expertos en usabilidad que estudian el comportamiento de los usuarios y hacen adecuaciones para facilitar el uso de la aplicación. Por ejemplo, las sugerencias de Google, el buscador de Facebook, o la forma de enviar tweets a través de Twitter, todas han sido planificadas por expertos en usabilidad.
¿Cómo puedo deducir que para el SIPE no consiguieron a ningún experto en usabilidad, aún cuando en Panamá hay varios? La usabilidad se rige usualmente por un set de reglas establecido, que prácticamente son mandamientos entre los desarrolladores. Por ejemplo, la regla de los 3-clics dice que el usuario debe llegar a lo que quiere o necesita en menos de tres clic. También hay reglas con respecto al diseño, como por ejemplo dar énfasis a la acción que más realizan los usuarios y hacerla resaltar entre todas. Por ejemplo, en el caso del SIPE, esta acción es la planilla. Por lo que vi del SIPE, no hay ningun elemento visual que te dirija hacia las acciones más comunes. Vamos a demostrar con el ejemplo. La imagen a continuación es de una aplicación gratuita llamada Mint. Esta aplicación es para la planificación financiera.
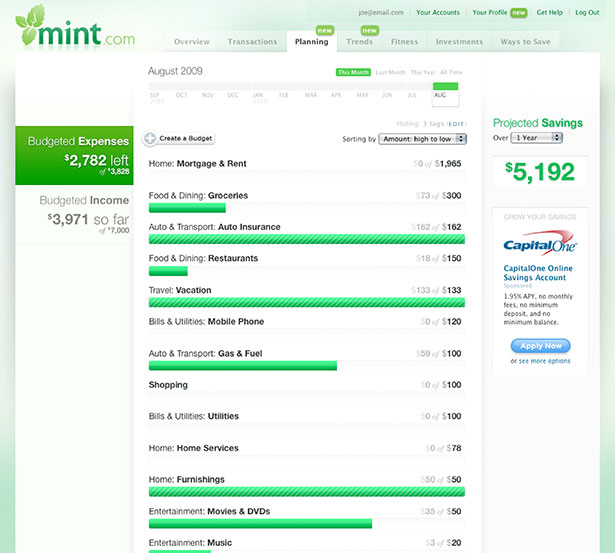
Aquí podemos ver la interfaz gráfica de Mint. Nótese el énfasis que se le da a una parte específica, que es la cantidad del presupuesto restante. Imagen: [Web Designer Depot](http://www.webdesignerdepot.com/2010/02/showcase-of-great-web-app-interfaces/)
Si te fijas en la imagen de arriba, ves una interfaz limpia. Los desarrolladores y expertos en usabilidad decidieron darle enfoque a lo más importante en la página: cuánto dinero del presupuestado aún queda disponible. Y el resaltado en verde ayuda visualmente a que lo ubiques rápidamente. En el SIPE, vemos totalmente lo contrario; correción, no vemos absolutamente nada. Esto es lo que se llama usabilidad. Lo que los expertos tratan de lograr es una aplicación cuya curva de aprendizaje, es decir la facilidad de aprender a usar la aplicación, sea mínima. Muchos diseñan la interacción para que sea tan fácil de usar que el usuario pueda aprender por si mismo, sin necesidad de capacitarse. Diganme, ¿alguno de ustedes necesitó asistir a un curso de capacitación para aprender a usar Facebook, o Twitter? Tal vez alguien te ayudó al inicio, pero rápidamente agarraste el hilo, ¿no es así? ¿Podrías decir lo mismo del SIPE?
La usabilidad es un paso del proceso. Lo que los expertos en UX crean es algo llamado wireframe. Un wireframe es técnicamente un bosquejo de la aplicación en donde se muestra donde están ubicados los elementos, y muchas veces como se interactúa con ellos. Usualmente se ven como la imagen que esta abajo, aunque suele variar según la complejidad de la aplicación.
Esto es lo que es un wireframe básicamente: un bosquejo de la aplicación. Imagen: [http://thecrumb.com/thecrumb/2011/02/11/wireframe-sketcher-a-better-alternative-to-balsamiq/](http://thecrumb.com/thecrumb/2011/02/11/wireframe-sketcher-a-better-alternative-to-balsamiq/)
Una vez se tienen los wireframes de la aplicación, entra al juego el diseñador gráfico. El trabajo del diseñador gráfico es hacer arte de los wireframes. Ellos o ellas son los encargados de crear la armonía de colores y todos los demás elementos gráficos de la aplicación, tales como los botones, íconos, etc. En Panamá existe una gran cantidad de diseñadores gráficos con talento excepcional. Es más, hasta exportamos talento. ¿Sabía usted que en Panamá se diseña y construyen varias de las páginas web de películas de Hollywood? Por ejemplo, la película Río, el sitio web fue hecho en Panamá, y si mal no recuerdo, creo que el de Transformers también. Los diseñadores son importantes porque le dan estética a la aplicación. La estética es sumamente importante porque contribuye a la usabilidad. Por ejemplo, en cuanto a colores, ¿sabía usted que las páginas con fondo azul y letras blancas tienden a agotar la vista rápidamente? Los colores, y la combinación de los mismos permite a una aplicación resaltar un área con el propósito de llamar la atención al usuario para una acción, y de esta forma hacer la interfaz y la aplicación mucho más amigable, como es el caso de Mint.
¿Cómo sé que para el SIPE no contrataron diseñadores gráficos? Los íconos de la aplicación. Los que he visto se consiguen en varios sitios web de Internet, gratis. Es más, yo he usado similares. Y para usarlos hay ciertas reglas que seguir, lo que me lleva a pensar algunas cosas. En primer lugar, no todos los íconos son para uso comercial. Muchos claramente dicen en su licencia y términos de uso, que son para uso personal exclusivamente, no para comercial. El SIPE es una aplicación hecha por terceros, y vendida comercialmente por lo que violaría entonces la licencia del creador del ícono. Ahora, muchos íconos se parecen. Habría que encontrar la fuente, es decir, el ícono original, y ver su licencia. Pero, ahora que el Presidente Martinelli sancionó el proyecto de ley 510 de 2012 y se convirtió en ley de la República, la recién creada DGDA podría empezar investigando a la CSS por violación a los derechos de autor.
Desafortunadamente, los desarrolladores del SIPE es obvio que no invirtieron en estos dos importantes componentes. Claman que es una interfaz amigable, pero ustedes los usuarios son los que mejor lo pueden juzgar. Desde mi punto de vista profesional, esa interfaz es un desastre, y no se justifica que, con un precio de 5 millones que salieron de nuestros impuestos, eso es lo que nos hayan entregado.
Interrogantes
Según tengo entendido, el SIPE fue desarrollado por X compañía. Sin embargo, hay dos cosas que me dejan con interrogantes. Si se fijan en la página de inicio del SIPE, abajo a la derecha hay un texto que dice Powered by 3SG Framework. Bueno, por curiosidad, me puse a investigar en Google sobre ese framework, y no absolutamente encontré nada, lo que me hace pensar que es un in-house framework, es decir, algo propio de los desarrolladores y no una solución abierta popular. Usar un framework así es un arma de doble filo: puede ser muy bueno, pero también muy malo. Pero bueno, no hablaré de eso porque eso es algo más técnico; tal vez para otro artículo.
La otra cosa que noté fue el logo de una empresa diferente a X compañía abajo a la derecha en la plataforma. A veces, cuando una empresa desarrolla una aplicación, coloca su logo como forma de publicidad. Entonces, ¿si X compañía fue la contratada para desarrollar el software, quién es esa que aparece abajo y por qué su logo aparece en el SIPE? Es más, ¿en la licitación o en el contrato no aparece nada sobre el branding? Me extraña que una entidad gubernamental permita hacer branding de una empresa privada en una aplicación pagada y desarrollada a un altísimo costo, y hospedada en un servidor y dominio de la institución. Será entonces que X compañía subcontrató a esta compañía para desarrollar el SIPE? Quiero aclarar, no tiene nada de malo subcontratar, pero entonces me gustaría que alguien me aclarara porque ahora mismo los panameños vemos a X compañía como a los desarrolladores de ese desastre. En fin, cualquiera que hizo el software, hizo un mal trabajo. Si no me creen, pregúntenle a cualquiera de los miles de usuarios molestos con el sistema.
Conclusiones
Desafortunadamente el SIPE llegó, y los empleadores van a tener que acostumbrarse a vivir con él, por más malo que sea. Lo bueno es que eventualmente el servicio va a mejorar (espero), si se hacen las cosas bien. A continuación las conclusiones a las que pude llegar del SIPE.
Desde la perspectiva del front-end, este es un trabajo patético. La calidad es pésima, no se invirtió en usabilidad o diseño. Ni siquiera tuvieron la delicadeza de contratar un diseñador para los íconos; pareciera que usaron los gratuitos de Internet. El resultado ya lo conocemos: el sistema más que un alivio se convirtió en un obstáculo. Desafortunadamente, al no poder ver el código fuente, no puedo opinar sobre el backend. Sin embargo, recopilando las experiencias de los usuarios puedo llegar a esta conclusión. Por 5 millones de dólares, nos entregaron un sistema mediocre que cumple su cometido y propósito, cuando funciona bien (lo que por lo visto por el momento, muy rara vez ocurre). Tal vez cumple con los requisitos del pliego en la licitación, pero lo que desarrollaron fue una plataforma mediocre en donde al parecer al desarrollador no le importó la calidad de su trabajo, solo entregar lo que se pidió y cobrar el cheque.
Es inaceptable que a estas alturas aún se esté realizando “mantenimiento”. La mayoría de la población no entiende lo que eso significa, pero los desarrolladores de Panamá lo entendemos claramente, y lo vamos a compartir con el resto del país. Mantenimiento es un eufemismo para no decir “nuestro programa está lleno de errores que vamos a tratar de corregir el fin de semana, o estamos agregando más recursos para que funcione mejor”. Como lo dijé anteriormente, en esta era, donde hay redundancia y backups para absolutamente todo, es un insulto que alguien nos diga “no puedes hacer nada porque el sistema está caído”. Aún en mantenimiento, el sistema no deberia estar caído. De haber planificación, habría redundancia, lo que significa que si estás haciendo “mantenimiento” en un servidor, puedes tener un segundo servidor ofrenciendo el servicio, y permitiéndole a las personas realizar los trámites. Que tengas que tumbar absolutamente TODO el sistema para brindar mantenimiento, significa que lo estás haciendo muy mal.
¿Qué cosas podrían haber hecho que esto no fuese la tragedia que los empleadores ahora tienen que soportar? En primer lugar, contratar empresas que se dedican realmente a desarrollar, no vender. X compañía son vendedores; venden Oracle. No son desarrolladores de nuevas tecnologías; no los verías usando MongoDB, o MSSQL o algo que no fuera de Oracle. Obviamente la solución que te van a entregar va a ser algo con Oracle. La CSS debió contratar una empresa que no vende software, sino que lo desarrolla. ¿Por qué? Porque estas empresas, en primer lugar, cuentan con mano de obra muy capacitada, muchas veces la mejor. ¿Por qué? Porque les pagan muy bien a sus desarrolladores, principalmente porque muchos de sus clientes son empresas extranjeras y no pueden darse el lujo de hacer desastres como lo que ocurrió con el SIPE. Empresas así estudian el problema, y seleccionan la mejor tecnología para desarrollar, y usan las mejores prácticas de la industria para asegurar un producto de excelente calidad. Son compañías que buscan la excelencia y siempre cumplen los requisitos, y ponen algo más de ñapa. No se aferran a desarrollar en la plataforma que venden. Por ejemplo, en un análisis corto, yo para este sistema hubiera usado Nginx como servidor HTTP, porque estaría esperando muchísimas conexiones concurrentes, y si es java la aplicación, JBoss o Tomcat (aunque no soy fanático de Java). Oracle ni siquiera hubiese pasado por mi mente. Claro, tengo que analizar lo que la CSS tiene. Si su base de datos es Oracle, no hay problema, me pego a Oracle. Pero la aplicación la desarrollo usando lo mejor para el caso. En lo personal, tal vez hubiera desarrollado la aplicación en PHP, aunque me inclino más hacia Ruby. Java probablemente no porque causa mucho overhead y esta es una aplicación de transacciones rápidas. Tal vez Node, pero mejor irse PHP o Ruby porque hay más gente capaz de dar soporte por si el desarrollador cierra.
Por otro lado, en cuanto a la arquitectura, francamente no lo hospedaría en el data center de Cable & Wireless, me hubiera ido por Amazon AWS. Pero aquí en realidad la culpa la tiene el gobierno. Existe un pánico entre las entidades del gobierno con respecto a la ubicación de los servidores. Tienen que estar o en la institución o en un lugar seguro en el país (por ende el data center de Cable & Wireless que cobra bien** caro). Propones colocar el software en la nube, que es mucho más económico y flexible, pero no quieren. Es como un miedo infundado que tienen conque el servidor no esté físicamente en el país. El SIPE, de haber estado en la nube de Amazon, esto es lo que yo hubiese hecho:
- Adquirir dos instancias large (8 GB de RAM) de Amazon EC2. Ambas estarían detrás de un load balancer que usaría la carga del servidor como métrica, con persistencia de sesión y que se encargue del SSL. Así divido el peso de la aplicación entre los dos. El SIPE estaría hospedado independientemente en ambos. Además, para cuando el tráfico lo requiera, o se presentáse una situación irregular, tendría dos instancias large de Amazon apagadas. Si se necesitan, se arrancan y en menos de un minuto apoyan la plataforma. Cuando no se necesiten, simplemente se apagan y se ahorra ese dinero.
- La base de datos, bueno no estoy seguro de si el SIPE se pega directo a la base de datos de la CSS, o utiliza específicamente una que se desarrolló para la aplicación. De ser el segundo caso, dos instancias large de Amazon RDS, con redundancia. De no ser así, bueno, me conectaría a la base de datos de la CSS a través de VPN.
- Para seguridad, y segregar el sistema de la nube, crearía una VPC en Amazon. Estaría conectada por VPN a la red de la CSS y quedaría excluída del resto de la nube.
Lo anterior son detalles técnicos. Básicamente lo que permitiría es satisfacer la demanda cuando se incrementa, es decir, cuando todos empiezan a enviar su planilla preelaborada. Esta arquitectura permitiría que el servicio se brinde sin interrupciones ni “el sistema está caído” o el “llevo 2 horas tratando de entrar y nada”. Es más, en caso de mantenimiento, se apagan dos servidores para darles el mantenimiento, y los otros dos de respaldo toman su lugar, asegurando que nunca se interrumpa el servicio. Cabe resaltar que esta configuración depende mucho de la eficiencia de la aplicación, y por lo que he visto del SIPE, no es muy buena (en serio, 7.9 MB de basura me envío en la primera carga; sin eso, la página no abre).
¿Se justifican los 5 millones? A mi parecer no. Igual tendría que revisar el pliego de cargos, pero por lo que he visto no. Por 5 millones, la interfaz debería ser estupenda y no debería haber problemas graves, tal vez los pequeños que siempre se escapan, pero no miles de empleadores formando fila y quejándose que no funciona. Ahora, no he visto el pliego de cargos, y no sé si los 5 millones incluye operación también, es decir, los costos del datacenter por x año. Pero, cualquier desarrollador como yo, que examine la aplicación les dirá lo mismo: nos conguearon nuevamente.
Actualización – 13 de octubre de 2012
En primer lugar, siguiendo recomendaciones para evitar problemas legales, eliminé los nombres de las compañías involucradas en el SIPE. Las he cambiado en el artículo por X compañía y Y compañía. Si deseas saber los nombres, puedes averiguarlos en los tantos artículos que hay en los periódicos que hablan del SIPE.
El día de ayer leí un artículo en la Estrella de Panamá (puedes ver el artículo aquí), que me aclararon unas cuantas dudas. En primer lugar, SIPE no fue desarrollado por X compañía únicamente. Más bien, fue desarrollado por un consorcio entre X compañía y Y compañía. Al menos ya tengo aclarado quién es Y compañía, que aparece abajo en el SIPE. Sin embargo, por lo visto en la plataforma, no veo el logo de X compañía en ningún lado, lo que me hace pensar que el SIPE en realidad fue desarrollado por Y compañía.
Por otro lado, en el artículo mencionan otras excusas que da la CSS para justificar el mal funcionamiento de la plataforma. Es más, voy a citar el artíclo:
Una fuente ligada al proceso de implementación dijo que la plataforma del programa no tiene la capacidad para soportar la base de datos, lo que ocasionó que colapsara. Artículo en La Estrella de Panamá – 12 de octubre de 2012
Quisiera alguien me explicara cómo un programa no tiene capacidad para soportar la base de datos. Se supone que estás diseñando la aplicación alrededor de la base de datos. ¿Cómo es posible entonces que tu programa no soporte la base de datos? Entendería si fuera al revés, que el servidor de la base de datos no tiene suficiente capacidad para atender las solicitudes del programa, pero ¿que el programa no soporte la base de datos? “Ahh bueno este, es que diseñamos el software pensando en MySQL y cuando fuimos a instalarlo nos dimos cuenta que debimos hacerlo pensando en Oracle y oops, bueno a reescribir los modelos porque estamos usando autoincrements y otras cosas específicas de MySQL, y tampoco usamos Data Objects para accesar la base de datos como debimos haber hecho desde un principio. Pero bueno, ya vimos nuestro error y esperamos que los aproximadamente 10 mil usuarios del SIPE no lo hayan notado.”
Nuevamente puedo deducir que están improvisando con el SIPE. No hicieron las pruebas necesarias antes de lanzarlo, no se aseguraron de tener los recursos suficientes, no tienen load balancing en sus servidores, en fin, es un desastre y hay miles de empleadores que piensan lo mismo. Y peor lo veo ahora que leí ese último artículo en donde se habla de adendas para perfeccionar el SIPE. En realidad el SIPE costó 6 millones más 200 mil adicionales por “capacitación”. Un millón quinientos mil en adendas para “adecuar” el SIPE, y aún no funciona. ¿De que otra forma se puede llamar eso?